60 MCP tools across 14 categories. 7+ Qdrant collections with tiered lifecycle. 15 n8n workflows for brain-inspired consolidation. A two-layer hook architecture with tool facades, constitutional alignment, and heuristic recording. Local Ollama embeddings. Zero cloud dependency.
AI coding agents lose all context between sessions. Every new conversation starts from zero — no memory of past decisions, solved problems, learned patterns, infrastructure knowledge, or operational procedures. This makes agents structurally incapable of improvement.
But memory isn't just storage. Raw session data needs consolidation into knowledge. Knowledge needs to decay when outdated. Contradictions need detection and resolution. Agent identities need provenance tracking. Sensitive content needs classification and access control. Tool usage patterns need to reinforce successful workflows and let failed patterns fade. And all of this needs to happen automatically.
The deeper architectural challenge is that Claude Code reads hooks from settings.json, not from plugin manifests. Hooks defined only in plugin.json don't fire for PostToolUse or Stop events. This means the hook architecture must be two-layer: settings.json for the hooks CC actually executes, and plugin hooks.json for the plugin lifecycle management that CC does read.
The hot path handles real-time session interaction via MCP tools. The cold path handles background maintenance via n8n. They never block each other. The hot path is fail-open — if Qdrant is down, sessions continue with flat-file memory.
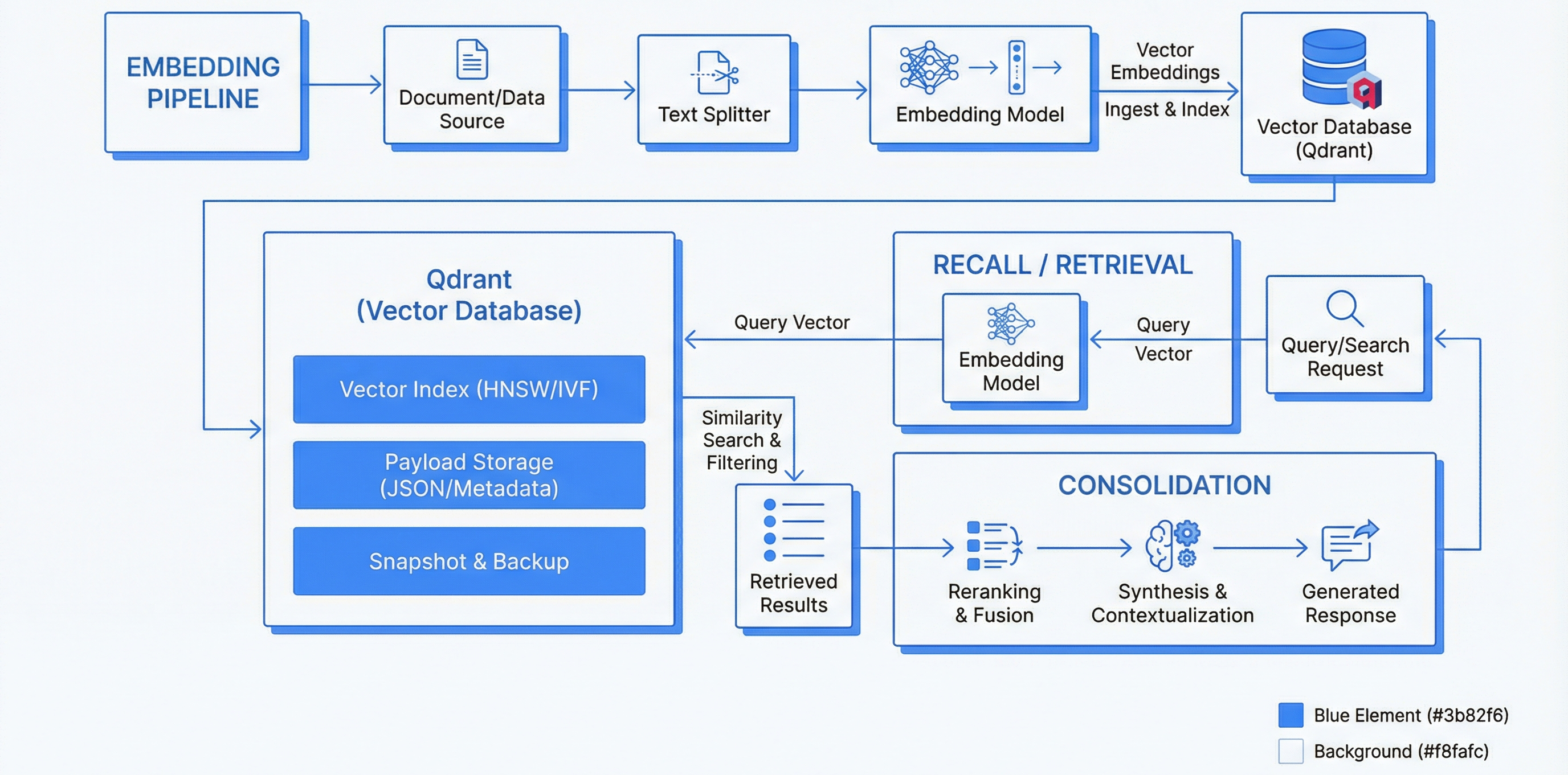
Trigger: Claude calls MCP tools (60 available)
Flow: MCP Server (Node.js) → Ollama (nomic-embed-text, 768-dim) → Qdrant
Latency: <500ms p95 recall, <1s p95 store
Also: Tool Facade scripts intercept Grep/Glob and serve memory content directly — Claude doesn't need to "decide" to check memory
Trigger: 15 scheduled n8n workflows
Flow: n8n → Qdrant API → batch operations (2 use LLM inference)
Cadence: Every 2h (extraction), 6h (compaction), daily (consolidation, TTL, tier transfer, decay), weekly (pruning, abstraction, permissions), monthly (governance)
Claude Code only reads hooks from settings.json for PostToolUse and Stop events. Plugin hooks.json works for SessionStart and PreToolUse but not reliably for all event types. The solution: wire critical hooks in both places.
| Service | Image | Port | Purpose |
|---|---|---|---|
| Qdrant | qdrant/qdrant:latest | 6334 | Vector database — 7+ collections, API key auth, persistent volumes |
| Ollama | Native binary | 11434 | nomic-embed-text (768-dim), llama3.3:70b (reasoning), qwen3.5:35b (MoE) |
| n8n | n8nio/n8n:latest | 5679 | 15 workflow automations, PostgreSQL backend, Anthropic API for LLM workflows |
| PostgreSQL | postgres:16-alpine | 5436 | n8n state, structured data, health-checked with pg_isready |
| MCP Server | Node.js process | — | 60 tools via MCP protocol, Qdrant + Ollama backends |
| Supabase | Studio + services | various | Backend-as-a-Service with auto-reconnect health checks |
| Collection | Purpose | Retention |
|---|---|---|
| claude_memories | Long-term persistent knowledge | Permanent (protected) |
| short_term_memory | Current session context | TTL-based decay |
| working_memory | Active task scratch space | 60-min TTL default |
| learnings | Domain knowledge patterns | Protected (never pruned) |
| procedures | Reusable step-by-step workflows | Protected (never pruned) |
| trajectories | Tool call sequences for few-shot | Decay-based |
| episodes | Full task execution records | Consolidation-eligible |
| heuristics | Task outcome metrics from task_outcome.py | Feeds self-assessment |
| pheromone_trails | Stigmergy — successful tool chains | Daily decay + evaporation |
| causal_analysis | Failure→fix patterns | Long-term |
| constitutional_assessments | Alignment drift observations | Session-scoped, flushed at Stop |
memory_store (temporal classes: permanent/decaying/deadline/periodic, sensitivity levels, decay halflives), memory_recall (semantic search), memory_forget (two-step search-then-delete), memory_scratch (ephemeral TTL workspace), memory_verify (reset decay clock), memory_boost (Noguchi self-organizing relevance)
memory_promote (tier transfer), memory_consolidate (episodes→facts→principles→heuristics), memory_prune (soft-delete to cold), memory_organize (knowledge graph: link/traverse/cluster), memory_summarize, memory_impact (causal assessment), hippocampal_consolidation (5-phase brain-inspired)
memory_provenance (chain tracing), memory_trace (upstream/downstream causal edges), contradiction_check (detect + resolve), session_recalled (for Noguchi boosting at session end)
episode (start/update/complete/search), learning (store with domain + error type), procedure (capture with trigger conditions), trajectory (tool sequences with feedback)
governance_report (ISO 42001 evidence), governance_gap_analysis, compliance_dashboard (ISO 42001 + EU AI Act + OWASP Agentic Top 10), constitutional_contract (monotonically decreasing privilege chains), constitutional_monitor (real-time drift detection), guardrail_proof (Ed25519 + Merkle attestation), data_sovereignty (jurisdiction tagging + GDPR cascading delete)
agent_identity (PQC-ready, key rotation, C-BOM), nhi_lifecycle (spawn/escalate/terminate), parl_coordinator (advisory locks, heartbeat), a2a_protocol (JSON-LD agent cards), task_specialization (performance routing scores), bft_consensus (weighted voting), federation (cross-instance sync with Ed25519)
agent_marketplace (publish/install/certify), agent_dev_env (isolated dev with hot-reload), meta_agent (underperformer detection), digital_twin (sandbox scenarios + promotion reports)
causal_debug (counterfactuals), flow_debug (DAG visualization), time_travel (session replay + what-if), semantic_diff (behavioral diffs between versions), self_assess (memory-grounded task assessment)
benchmark, benchmark_suite (7-dim + regression detection), cost_router (3-tier Haiku/Sonnet/Opus cascading with budget tracking), stigmergy (pheromone trail reinforcement + decay guidance)
rag_search (Obsidian vault), predictive_preload, context_budget (5 compartments), temporal_planner (dependencies + critical path), workflow_author (NL→conductor), workflow_optimizer (bottleneck A/B testing), micro_swarm (BFT consensus aggregation), skill_discovery
formal_verify (safety/liveness/invariant checks, Ed25519 certificates), red_team (6 attack categories: goal hijacking, tool misuse, privilege escalation, memory poisoning, prompt injection, data exfiltration)
world_model (predict outcomes, observe actuals, update service models), multimodal_input (images, audio, diagrams → structured text)
| Workflow | Schedule | Nodes | Purpose |
|---|---|---|---|
| Session Extraction | Every 2h | 13 | LLM extracts structured memories from raw session transcripts |
| Memory Compaction | Every 6h | 12 | Cluster similar memories, summarize, archive originals |
| Predictive Patterns | Daily 2AM | 10 | Mine trajectories for recurring tool chain patterns |
| Hippocampal Consolidation | Daily 3AM | 16 | Brain-inspired hot→warm consolidation with cycle audit |
| TTL Sweep | Daily 3AM UTC | 8 | Universal GC — expire points across all collections |
| Tier Transfer | Daily 3:30AM | 14 | Promote warm→long-term + delete expired cold |
| Stigmergy Decay | Daily 4AM | 7 | Pheromone trail decay + evaporation below threshold |
| Active Pruning | Weekly Sun 5AM | 13 | Demote underused memories to cold + audit trail |
| Hierarchical Abstraction | Weekly Sun 4AM | 15 | LLM synthesis into higher-level abstractions + dedup |
| Permission Review | Weekly Mon 6AM | 6 | Audit NHI lifecycle for stale permissions |
| Monthly Review | 1st of month | 8 | 4-way governance report → Obsidian (expiring, never-accessed, sensitive, redactions) |
| Memory Gateway | Webhook | 14 | Real-time API — store/recall/rag with auth routing |
| Benchmark Regression | Scheduled | 2 | Performance regression detection |
| Compliance Report | Scheduled | 2 | Compliance evidence generation |
| Skill Discovery | Scheduled | 2 | Emergent skill pattern detection from trajectories |
2 workflows use LLM inference (Session Extraction + Hierarchical Abstraction call Claude via Anthropic API). 3 are lightweight stubs. The Memory Gateway is the only webhook-triggered workflow — all others run on schedule.
Intercepts Grep and Glob calls. Before the tool executes, the facade embeds the search query, queries Qdrant, and if memory has the answer, serves it directly as the tool result. Claude never needs to "decide" to check memory — the answer appears as if the search found it.
Fires on every tool call. Checks actions against session objectives for scope drift, target drift, and destructive operations. Flags are buffered to JSONL and flushed to constitutional_assessments collection by flush_insights.py at Stop. No LLM calls — must complete in <2s.
Stop hook. Reads the tool chain buffer, classifies the task type, calculates success metrics, stores in the heuristics collection. Feeds the self-assessment system and dashboard. Must run before flush_insights.py.
Extended SessionStart hook. Beyond auto-recall, now runs self-assessment against the heuristics collection and sets constitutional objectives for the session. These objectives are what the constitutional observer checks against.
Build a persistent vector memory system for Claude Code:
1. MCP SERVER (Node.js, 60 tools across 14 categories):
- Core CRUD: store (temporal classes, sensitivity, decay halflife), recall,
forget (two-step), scratch (ephemeral TTL), verify (reset decay), boost (Noguchi)
- Lifecycle: promote (tier transfer), consolidate (episodes→heuristics),
prune (soft-delete to cold), organize (knowledge graph), summarize,
impact assess, hippocampal consolidation (5-phase brain-inspired)
- Provenance: trace causal chains, contradiction detection/resolution
- Episodic: episodes, learnings, procedures (with triggers), trajectories
- Governance: ISO 42001 + EU AI Act + OWASP scoring, constitutional contracts,
guardrail proofs (Ed25519+Merkle), data sovereignty (GDPR cascading delete)
- Agent Identity: PQC-ready, NHI lifecycle, parallel coordination, A2A protocol,
BFT consensus, federation (Ed25519 keypairs)
- Debugging: causal debug, flow debug, time-travel, semantic diff, self-assess
- Performance: benchmarks, cost routing (3-tier cascade), stigmergy trails
2. QDRANT COLLECTIONS (7+ tiered):
- claude_memories (permanent), short_term_memory (TTL), working_memory (60min),
learnings (protected), procedures (protected), trajectories (decay), episodes
- Plus: heuristics, pheromone_trails, causal_analysis, constitutional_assessments
- Dedup at 0.92 cosine similarity, 1000 max per collection
3. TWO-LAYER HOOK ARCHITECTURE:
- Layer 1 (settings.json — what CC actually reads):
SessionStart: auto-recall script
UserPromptSubmit: embed prompt → Qdrant search → inject context
PreToolUse: Tool Facade (intercepts Grep/Glob, serves memory as result),
constitutional observer (drift detection on every tool call)
PostToolUse: tool chain tracker, world model observer
Stop: task outcome → heuristics, flush insights → stigmergy + constitutional
SessionEnd: transcript capture, Obsidian daily note
- Layer 2 (plugin hooks.json): session_start (self-assessment + objectives),
pre_store, auto_linker, pre_compact, assistant_response_capture
4. N8N WORKFLOWS (15 active):
- Session Extraction (2h): LLM transcript → structured memories
- Memory Compaction (6h): cluster → summarize → archive
- Hippocampal Consolidation (daily 3AM): 5-phase hot→warm
- Tier Transfer (daily 3:30AM): warm→LT + cold expiry
- Stigmergy Decay (daily 4AM): pheromone evaporation
- Active Pruning (weekly): demote to cold + audit
- Hierarchical Abstraction (weekly): LLM synthesis + dedup
- Permission Review (weekly): NHI audit
- Monthly Review: governance report → Obsidian
- Memory Gateway (webhook): store/recall/rag API
5. DOCKER COMPOSE: Qdrant, PostgreSQL, n8n (with Anthropic API key),
Supabase (with reconnecting health checks), Ollama native on host
Build as MCP server + Claude Code plugin + n8n workflow definitions.
Wire hooks in BOTH settings.json and plugin hooks.json.Claude Code's hook loading has a gap: PostToolUse and Stop from plugin hooks.json don't always fire. Wiring critical hooks in settings.json guarantees execution. The plugin layer handles SessionStart and PreToolUse where plugin loading works. Both layers reference the same Python scripts.
Requiring Claude to "decide" to check memory before searching is fragile — it often skips it under context pressure. The Tool Facade intercepts Grep/Glob searches and serves memory results directly. Claude gets the answer without needing to make the right decision.
Checking alignment after the session is too late. The constitutional observer runs on every tool call in <2s, buffering drift flags. The flush at session Stop writes them to Qdrant for trend analysis. Real-time detection, batch storage.
Task outcome recording creates a feedback loop: session N's task_outcome.py writes to heuristics → session N+1's session_start.py reads heuristics for self-assessment → better task routing and risk awareness. The system gets better at knowing what it's good at.
Separating concerns means each workflow runs independently at the right frequency. A slow LLM synthesis (weekly) never blocks a fast TTL sweep (daily). Each workflow can fail without affecting the others. The original 2-workflow approach (organize + forget) couldn't scale.
Pheromone trails encode successful tool chains through observation, not programming. Daily decay prevents stale patterns from dominating. Agents get probabilistic guidance ("87% success rate for this pattern") instead of rigid rules. The system learns what works by watching what works.
Memory operates as a Claude Code plugin with both settings.json and plugin hooks.json wiring. 6 slash commands (/memory-search, /memory-save, /memory-resume, /forget, /memory-stats, exit) provide user-facing interfaces. MCP server registered via .mcp.json.
7 governance tools connect memory to the governance framework. Constitutional contracts and monitor tools enforce delegation chain privileges. Data sovereignty and guardrail proofs provide compliance evidence. The governance plugin's policy engine evaluates memory writes.
Conductor stores trajectories, learnings, and task outcomes. Agent identity, NHI lifecycle, BFT consensus, and task specialization tools support the conductor's 29-agent workforce. The conductor state schema references governance manifests stored in memory.
Context budget management (5 compartments) bridges memory and context window management. PreCompact hooks trigger emergency state saves. Predictive preloading reduces recall latency by pre-fetching likely-needed memories based on trajectory patterns.
| Component Down | Impact | Fallback |
|---|---|---|
| Ollama | Cannot embed | Session continues with MEMORY.md (flat file) |
| Qdrant | Cannot store/recall | Empty results; MEMORY.md still loads |
| n8n | Maintenance stops | Vectors accumulate; manual run when restored |
| PostgreSQL | n8n state lost | MCP continues; n8n workflows pause |
| Supabase | Dashboard disconnects | Auto-reconnect health check restores connection |
| Metric | Target |
|---|---|
| memory_recall latency | <500ms p95 |
| memory_store latency | <1s p95 |
| Dedup false positive rate | <1% |
| Constitutional observer latency | <2s per tool call |
| Weekly prune coverage | 100% of collections scanned |
| Backup freshness | <7 days |
The debug-memory diagnostic checks all 6 hops: Ollama process + API + model, Qdrant container + API + all collections, MCP server + hooks, n8n container + API, hook pipeline integrity, and Memory Dashboard container.