29 specialized agents coordinated through an 882-line state schema. 5-signal tier classification. 10 verification gates. Independent Gemini validation of every agent run. NHI lifecycle tracking. Circuit breakers. Cost tracking. BRD-driven development with intent engineering.
A single AI agent handling a complex task — "build an authentication system with OAuth, MFA, and session management" — produces inconsistent results. It tries to architect, implement, test, and review simultaneously. Under context pressure, it skips steps, doesn't validate its own output, and produces code that works in isolation but fails integration.
Worse: agents routinely claim completion when work is partial, stubbed, or wrong. Self-reporting is unreliable. An agent that wrote the code should not be the one validating it — the same way a developer doesn't review their own pull request.
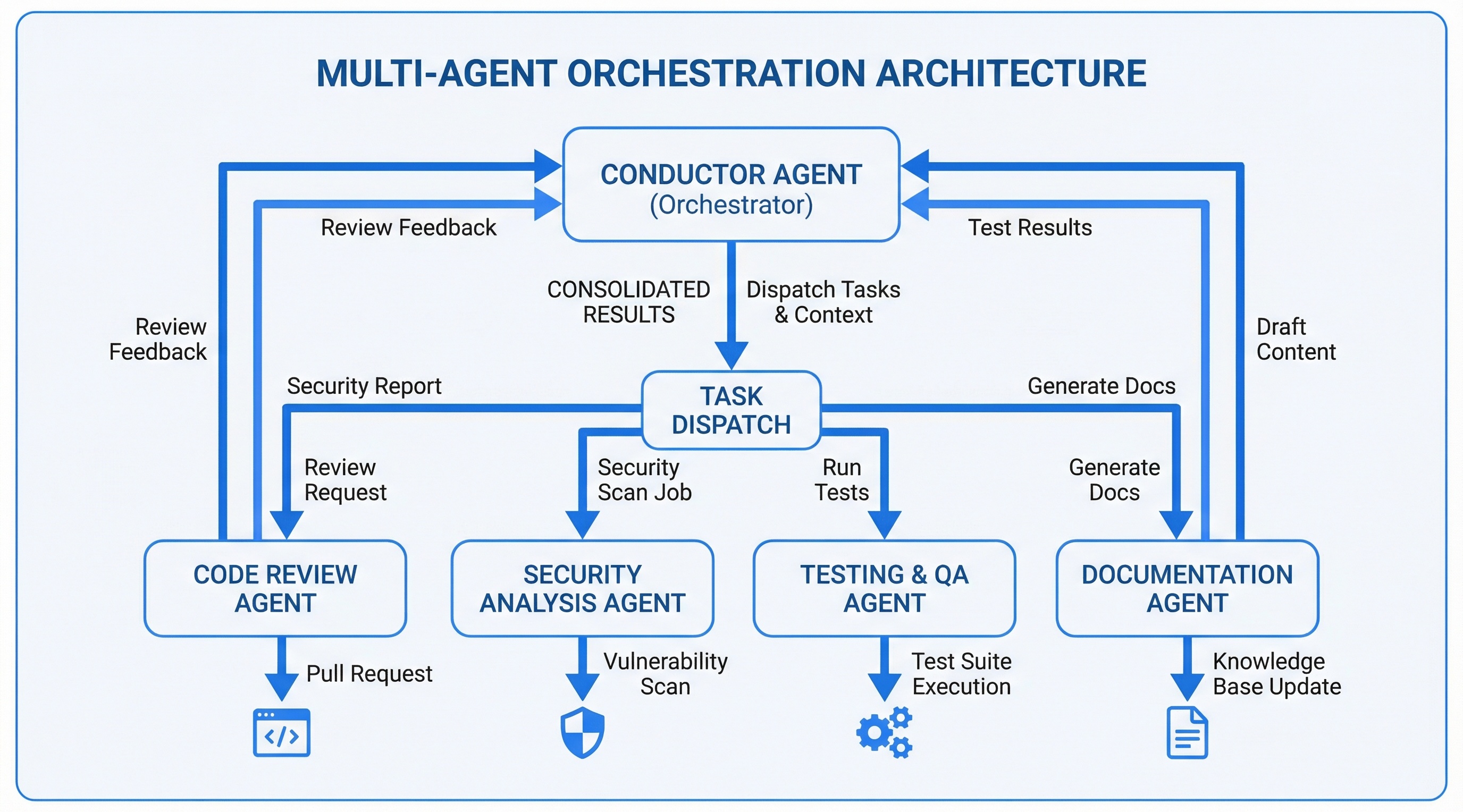
Human development teams solve this with specialization, quality gates, and independent review. The orchestration system brings the same structure to AI agents: 29 specialized agents working through tiered workflows with 10 verification gates, independent Gemini validation of every agent output, and persistent state tracking.
The key insight: not every task needs the full pipeline. A typo fix doesn't need architecture review. A greenfield system does. The 5-signal tier classification matches orchestration complexity to task complexity.
| Signal | Weight | Evaluates |
|---|---|---|
| Scope | 0.30 | File count, cross-domain impact, system breadth |
| Type | 0.25 | Bug fix → feature → refactor → architecture → greenfield |
| Risk | 0.25 | Blast radius, data sensitivity, reversibility |
| Ambiguity | 0.20 | Spec completeness, requirement clarity, unknowns |
| Intent Sensitivity | bonus | Compliance/security/financial tasks auto-escalate |
Every agent dispatch follows the same accountability loop. The orchestrating agent (Claude) dispatches work, but a separate AI (Gemini CLI) independently validates the output. Claude does not grade its own homework.
| Gemini Verdict | Completion | Conductor Action |
|---|---|---|
| PASS | 100% | Proceed to next step |
| PARTIAL | ≥70% | Proceed with advisory warning logged |
| PARTIAL | <70% | Block — finding-level remediation loop |
| FAIL | any | Block — remediate or escalate to human |
| ERROR | n/a | Log, proceed (Gemini unavailability is non-blocking) |
When Gemini rejects an agent's output, the system doesn't just re-run the entire task. It extracts each specific finding and dispatches targeted fixes:
Every finding has a paper trail: what Gemini flagged, what Claude changed, whether Gemini accepted the fix.
The conductor maintains a comprehensive state object validated against a JSON schema after every Write/Edit operation. Key domains tracked:
project_name, tier signals, current phase/step, task queue, completed tasks with outcomes/deliverables
Agent instances with IDs (nhi_*), spawn/terminate times, status, parent NHI, tools used, token usage
9 trigger types (phase_transition, agent_handoff, pre_ciso_review, pre_auto_code, etc.), git SHA, BRD hash
Blocked tasks (reason, since, by_step) and failed tasks (8 failure types, retry count, escalation status)
budget_limit_usd, total tokens in/out, estimated_cost_usd, budget_exceeded flag
closed/open/half_open states, failure count, opens_at threshold, half_open cooldown
Objectives (goal, signals, priority, constraints), trade-offs, delegation boundaries, prohibited behaviors
manifest_id/version/hash, trust_level 1-5, session_classification, audit_session_id, human_gate_required
Per-agent validation audit trail: verdict, completion %, deliverables checked/passed/failed, finding resolutions (RESOLVED/UNRESOLVED/REGRESSED), attempt counts, aggregate stats
post_ciso, post_extraction, post_architect, post_qa, post_implementation, post_documentation, post_pentest, post_supply_chain, pre_release, completeness
A YAML capability matrix maps task types to agents based on capability match + trust level. The orchestrator selects best-fit agents for each phase. Fallback routing handles unavailable agents.
User Requirements → BRD (Research) → Intent Engineering (Section 3.6)
→ Technical Spec (Architect) → Implementation Plan (Builder)
→ Code (Builder) → Tests (QA) → Security (CISO) → Review → MergeEvery STANDARD/MAJOR workflow starts with a Business Requirements Document, not code. The BRD includes Section 3.6 (Intent Engineering) capturing objectives, constraints, trade-offs, and delegation boundaries. BRD-tracker.json maintains traceability from extraction through completion.
The state schema detects and tracks: has_api, has_ui, has_database, has_containers, has_kubernetes. Plus deployment_target (local/cloud/hybrid/on-premise), compliance_requirements (SOC2/GDPR/HIPAA/PCI-DSS/ISO27001/FedRAMP), security_classification, and PQC readiness assessment.
After every agent dispatch returns, the conductor runs independent validation via Gemini CLI before proceeding. This is mandatory for all agents that produce file artifacts.
Used after initial agent dispatch. Gemini receives the agent's task description, expected deliverables, actual files changed (via git diff), and the agent's self-reported output. Returns a structured PASS/FAIL/PARTIAL verdict with per-deliverable evidence.
Used in the remediation loop after Claude has attempted fixes. Gemini receives only the original findings and Claude's resolution evidence. Returns per-finding verdicts: RESOLVED, UNRESOLVED, or REGRESSED. PASS requires all findings resolved.
Every validation is recorded in conductor-state.json with: validation ID, agent name, verdict, completion percentage, deliverables checked/passed/failed, specific issues found, attempt number, phase/step context, and the action taken by the conductor. Aggregate statistics track pass/fail/partial/error counts, re-dispatches triggered, and average completion percentage across the entire workflow.
If Gemini CLI is unavailable, the conductor logs a warning and proceeds. Gemini outage is non-blocking — it degrades the accountability guarantee but doesn't halt the workflow. The Gemini Validator itself is never recursively validated.
Build a multi-agent orchestration system for Claude Code:
1. TIER CLASSIFICATION: 5-signal weighted scoring (scope 0.30, type 0.25,
risk 0.25, ambiguity 0.20 + intent sensitivity bonus) → 1.0-4.0 score
→ TRIVIAL/MINOR/STANDARD/MAJOR tier workflows
2. STATE SCHEMA (882 lines): Validated JSON with:
- Workflow: project, tier, phase, step, task queue, completed tasks
- NHI Registry: agent instances (nhi_* IDs), spawn/terminate, parent lineage, tokens
- Checkpoints: 9 trigger types, git SHA, BRD hash, phase/step snapshot
- Dead Letters: blocked (reason, since) + failed (8 types, retry, escalation)
- Cost: budget_limit_usd, token in/out, estimated_cost, exceeded flag
- Circuit Breaker: closed/open/half_open, failure threshold, cooldown
- Intent: objectives, trade-offs, delegation_boundaries, prohibited_behaviors
- Governance: manifest_id/version/hash, trust 1-5, classification, audit_session_id
- Gemini Validations: per-agent audit trail (verdict, completion %, deliverables,
finding resolutions, attempt counts), aggregate stats
- 10 verification gates with advisory findings and severity breakdowns
3. 29 AGENTS (markdown files):
Core (15): orchestrator, critic, gemini-validator, checkpoint, builder,
architect, QA, QA review, CISO, research, project setup, code reviewer,
compliance, doc gen, completeness validator
Specialized (14): frontend, devops, database, API design/docs, performance,
observability, pentest, LLM security, n8n, analyze, bug find, refactor, advisor
4. GEMINI VALIDATION PROTOCOL:
After every agent dispatch, validate output via Gemini CLI independently.
Two modes: full validation (initial check) and targeted re-validation
(per-finding check after remediation). Verdicts: PASS/FAIL/PARTIAL/ERROR.
Finding-level remediation loop: each issue addressed individually with
cited evidence (file:line changed, rationale). Per-finding re-validation
returns RESOLVED/UNRESOLVED/REGRESSED. Max 2 remediation loops, then
escalate to human. Gemini unavailability degrades gracefully (non-blocking).
5. BRD PIPELINE: Requirements → BRD (Section 3.6 Intent Engineering) →
Technical Spec → Implementation Plan → Code → Tests → Security → Review
Tracked via BRD-tracker.json with extraction-to-completion traceability
6. CAPABILITY ROUTING: YAML matrix mapping task types to agents by
capability match + trust level. Fallback routing when specialist unavailable.
7. HOOKS: SessionStart (detect state, inject status), PostToolUse (validate
state schema on Write/Edit). Wire PostToolUse in settings.json.
Build as a Claude Code plugin with 29 agent .md files, state schema,
capability matrix, workflow templates, and hook scripts.Agents claiming "done" is unreliable — they skip steps, stub functions, and produce incomplete output under context pressure. Using a separate AI (Gemini CLI) as an independent validator eliminates self-grading bias. Finding-level remediation ensures each specific issue is addressed with evidence, not hand-waved away in a bulk re-run. The ~5-15 second overhead per agent dispatch is negligible compared to the cost of shipping incomplete work.
Strict JSON schema validation catches state corruption immediately. Every Write/Edit operation validates via PostToolUse hook. The schema documents every field, constraint, and relationship — it's both enforcement and documentation. Gemini validation results, finding resolutions, and aggregate stats all have explicit schema definitions.
Every agent instance gets a unique NHI ID, parent lineage, tool/token tracking, and explicit spawn/terminate lifecycle. This enables forensic tracing, cost attribution, and permission auditing at the individual agent level.
Max 2 retries, then escalate. The circuit breaker pattern (closed→open→half_open) prevents cascading failures. A failing agent doesn't burn the entire token budget — it trips the breaker and the orchestrator adapts.
Section 3.6 captures not just what to build but why — objectives with constraints, trade-offs with resolutions, delegation boundaries, and prohibited behaviors. This feeds the constitutional observer for drift detection during execution.
When remediation fixes specific findings, Gemini re-validates only those findings — not the entire output. This keeps the remediation loop tight and focused, avoids discovering new issues mid-fix, and provides clear per-finding accountability (RESOLVED/UNRESOLVED/REGRESSED).
The conductor is itself a plugin. 29 agents, 7 skills, hooks, and state management all use the plugin architecture. The two-layer hook system ensures state validation fires reliably on PostToolUse.
The state schema's governance block (manifest_id, trust_level, conductor_tier) feeds the governance policy engine's tier matrix. NHI lifecycle events emit to the audit bus. Human gates trigger at MAJOR tier + elevated tools.
Completed workflows generate trajectories and learnings stored in vector memory. Task specialization scores track agent performance. Gemini validation history informs future agent reliability assessments.
Multi-agent workflows consume context rapidly. The state schema's context management skill enforces a 60% budget rule. Context guard signals trigger checkpoint saves and phase pausing.
STANDARD and MAJOR tier workflows include a Code Hardener QA phase after implementation. Scan-fix-rescan cycles run until quality score reaches 1000, followed by adversarial dual-AI review (Claude + Gemini) with debate resolution for disputed findings.